
Customizing LLMs through Supervised Fine-tuning
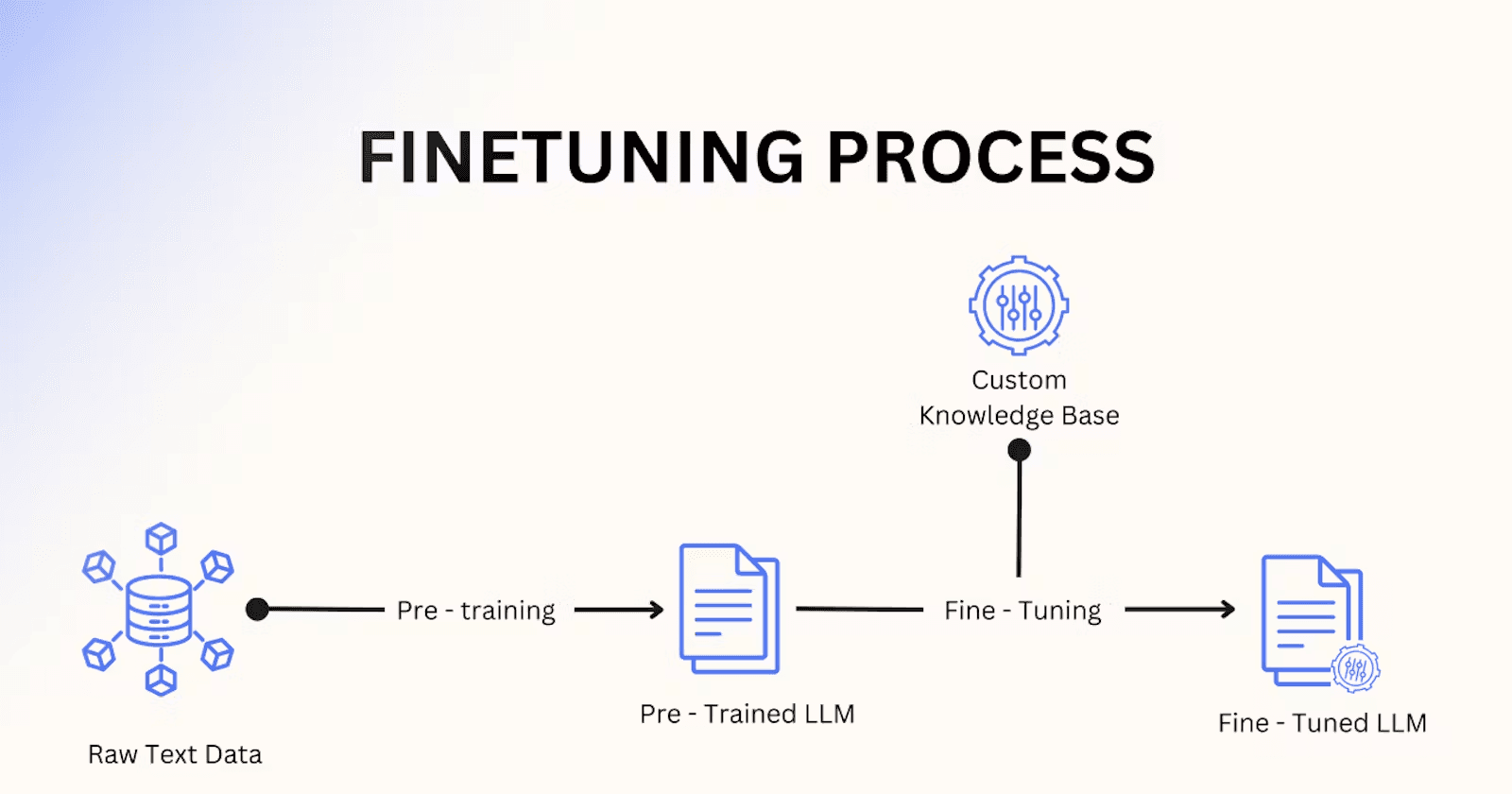
In the ever-evolving domain of Natural Language Processing (NLP), supervised fine-tuning has emerged as a game-changing technique for adapting pre-trained Large Language Models (LLMs) to specific tasks. While pre-trained LLMs like those in the GPT family have made significant strides in language comprehension and generation, they often lack optimization for particular applications.
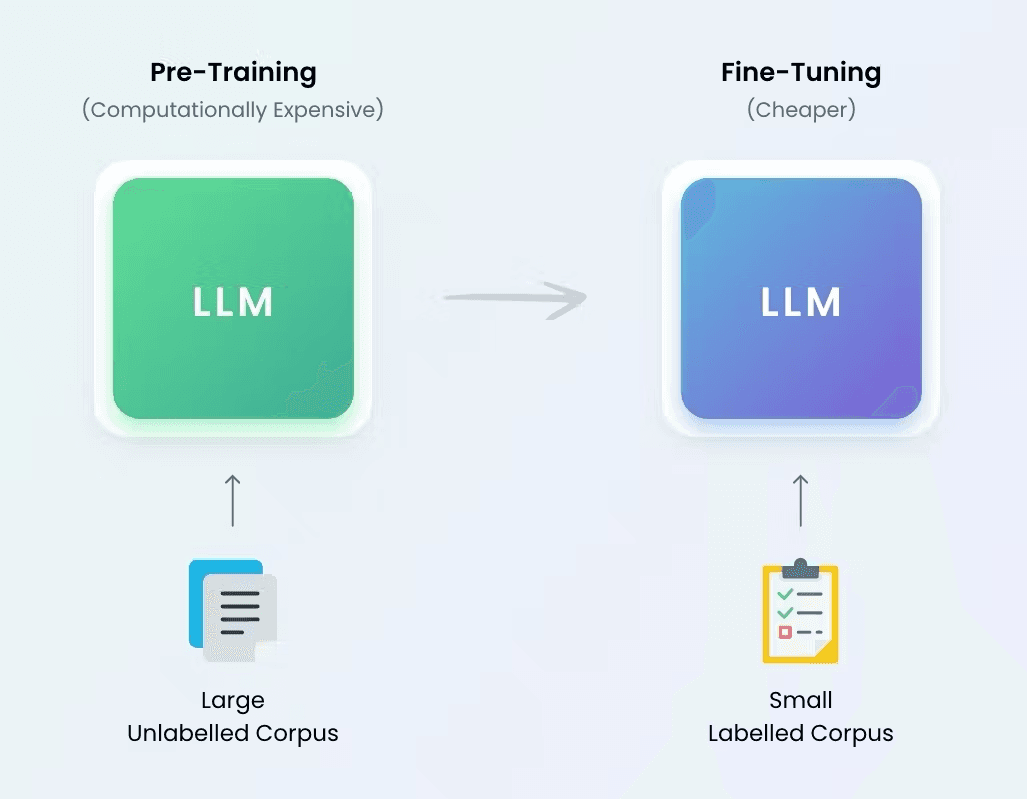
Supervised fine-tuning acts as a bridge, leveraging the broad language understanding acquired during pre-training and tailoring it to a target task through supervised learning. By fine-tuning a pre-trained model on task-specific data, NLP engineers can achieve remarkable results with considerably less training data and computational power compared to training from scratch. This is especially crucial for LLMs, as retraining with the entire dataset would be computationally unfeasible.
The effectiveness of supervised fine-tuning has led to numerous breakthroughs across various NLP tasks, establishing it as a standard practice in developing high-performance language models. Researchers and industry professionals continue to explore innovative approaches to fine-tuning, pushing the boundaries of what's possible in NLP.
In this article, we'll explore the process of fine-tuning an instruction-based LLM using two different approaches: the traditional method with the transformers library and the newer approach using the trl module.
Understanding supervised fine-tuning (SFT)
Supervised fine-tuning involves adapting a pre-trained LLM to a specific task using labelled data. The key distinction between SFT and unsupervised techniques lies in the validation of the fine-tuning data beforehand. While LLM training is typically unsupervised, fine-tuning is generally a supervised process.
During SFT, the pre-trained LLM is fine-tuned on a labelled dataset using supervised learning techniques. The model's parameters are adjusted based on the gradients derived from a task-specific loss function, which measures the difference between the LLM's predictions and the ground truth labels.
This process allows the model to learn task-specific patterns and nuances present in the labelled data. By adapting its parameters to the specific data distribution and task requirements, the model becomes specialized in performing well on the target task.
For instance, imagine you have a pre-trained LLM that responds to the query ”My order hasn't arrived yet. What should I do?” with a basic answer like "Check your order status online or contact customer support."

Above is a basic, generic response to a customer service query;
Now, let's say you want to create a chatbot for an e-commerce platform's customer service. While the initial response might be factually correct, it lacks the personalization and empathy expected in a customer service interaction. This is where supervised fine-tuning comes into play.
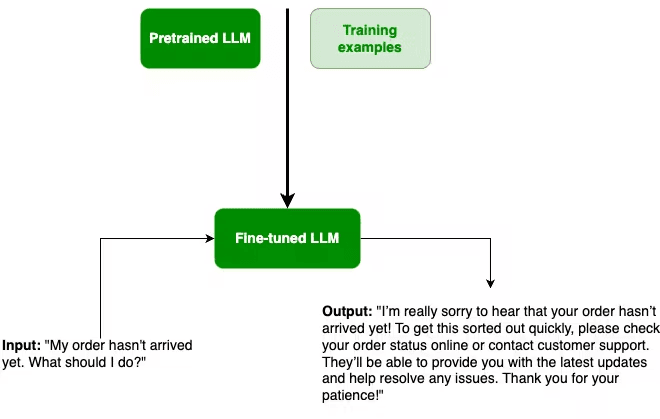
Above is an an improved, more empathetic customer service response;
By providing a series of validated training examples, your model can learn to generate responses that align with your specific customer service guidelines, incorporating some empathy, personalization, and brand voice.
Some key reasons why you may want to fine-tune an LLM include:
-
Generating responses that align with your organization's tone and guidelines
-
Incorporating specific or proprietary information not available during the initial training phase
-
Teaching the LLM to handle new, previously unseen types of prompts
-
Improving performance on domain-specific tasks
Supervised Fine-tuning using the Transformers Library
Huggingface's transformers library has become the go-to solution for training and fine-tuning models, including LLMs. The library's Trainer class has long been a core feature for model fine-tuning. However, with the introduction of the trl module for Reinforcement Learning, a new SFTTrainer class has been released, specifically designed for Supervised Fine-tuning of LLMs. Let's explore both approaches.
Fine-tuning with the Trainer Class
The Trainer class simplifies the process of pre-training and fine-tuning models, including LLMs. It requires the following key components:
-
A model, loaded using
AutoModelForCausalLM.from_pretrained -
TrainingArguments
-
Train and evaluation datasets
-
A DataCollator, which applies various transformations to the datasets, including padding and token masking for next-token prediction
from transformers import Trainer, TrainingArguments, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained("<YOUR_MODEL_HERE>")
training_args = TrainingArguments(
output_dir="./outputs", # overwrite the content of the output directory
overwrite_output_dir=True,
num_train_epochs=3, # number of training epochs
per_device_train_batch_size=8, # batch size for training
per_device_eval_batch_size=32, # batch size for evaluation
eval_steps=4000, # Number of update steps between two evaluations.
save_steps=8000, # after # steps model is saved
warmup_steps=500,# number of warmup steps for learning rate scheduler
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
)
To create the necessary datasets and collator, you might use code similar to this:
from transformers import TextDataset, DataCollatorForLanguageModeling
tokenizer = AutoTokenizer.from_pretrained("<YOUR_MODEL_HERE>")
train_path = "<TRAINING_DATASET_PATH>"
test_path = "<TEST_DATASET_PATH>"
def load_dataset(train_path, test_path, tokenizer):
train_dataset = TextDataset(
tokenizer=tokenizer,
file_path=train_path,
block_size=128
)
test_dataset = TextDataset(
tokenizer=tokenizer,
file_path=test_path,
block_size=128
)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False
)
return train_dataset, test_dataset, data_collator
train_dataset, test_dataset, data_collator = load_dataset(train_path, test_path, tokenizer)
For those looking to fine-tune instruction-based LLMs, here are some valuable datasets to consider:
-
AlphaCode: A dataset of competitive programming problems and solutions (Pairs, Multiple languages, 1.1M entries)
-
databricks-dolly-15k: Dolly2.0 (Pairs, English, 15K+ entries) — A dataset of human-written prompts and responses, featuring tasks like question-answering and summarization.
-
GPTeacher: (Pairs, English, 20k entries) — A dataset containing targets generated by GPT-4, including seed tasks from Alpaca and new tasks like roleplay.
-
GPT-4all Dataset: GPT-4all (Pairs, English, 400k entries) — A combination of some subsets of OIG, P3, and Stackoverflow, covering general QA and customized creative questions.
-
OASST1: OpenAssistant (Pairs, Dialog, Multilingual, 66,497 conversation trees) — A large, human-written, human-annotated high-quality conversation dataset aiming to improve LLM responses.
Fine-tuning with the trl SFTTrainer Class
The SFTTrainer class, which is part of huggingface's trl library, was developed to facilitate supervised fine-tuning as a step in Reinforcement Learning from Human Feedback (RLHF). While it inherits from the Trainer class, it introduces some additional capabilities that are particularly useful when working with LLMs. let’s have a look:
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
model = AutoModelForCausalLM.from_pretrained("<YOUR_MODEL_HERE>")
trainer = SFTTrainer(
model,
train_dataset=train_dataset,
evaluation_dataset=evaluation_dataset,
data_collator=collator
)
trainer.train()
You possibly haven’t noticed anything new from the above code, and it is pretty much because, as mentioned earlier the SFTTrainer class inherits from the Trainer function.
Here are a couple of key advantages of the SFTTrainer class:
- Integration with
peft: Support for the Parameter Efficient Fine-tuning library, which includes techniques like LoRA and QLoRA. These methods allow for fine-tuning only a subset of model parameters, significantly reducing computational requirements.
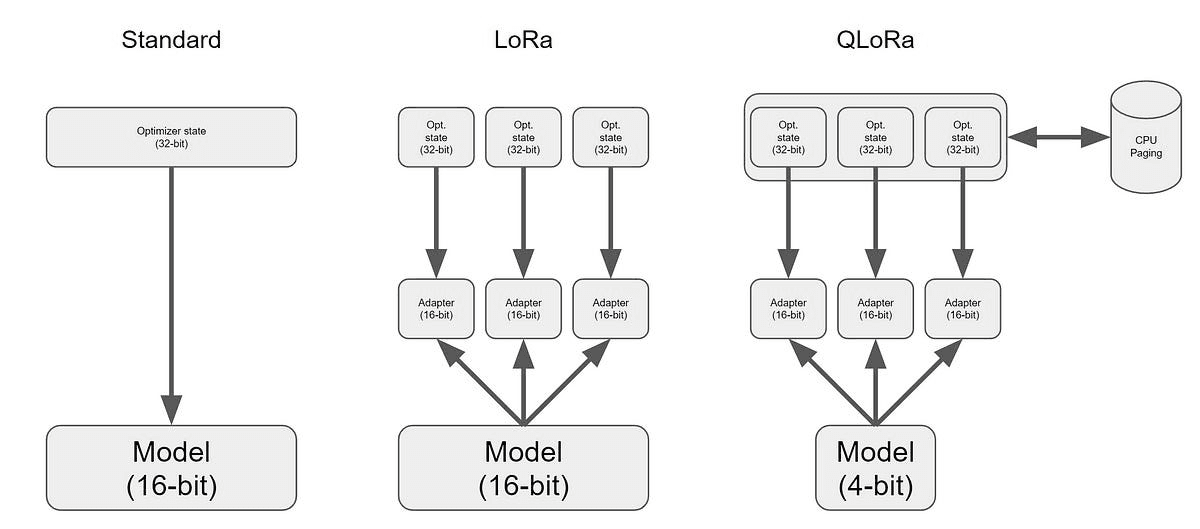
- Batch packing: Instead of padding sentences to a fixed length, packing allows for combining inputs sequentially, increasing batch processing efficiency.
Conclusion
Fine-tuning has proven to be an invaluable way in harnessing the full potential of Transformer architectures. Whether you're training a language model for next-token prediction, masking tasks, or specialized sequence classification, supervised fine-tuning allows you to leverage human-labelled data to achieve optimal results.
For Large Language Models trained on vast amounts of open-source data, fine-tuning becomes crucial for tailoring their outputs to specific needs and use cases.
The transformers library's Trainer class has long been a reliable option for fine-tuning transformer-based models. More recently, the trl library introduced the SFTTrainer class, which not only facilitates supervised fine-tuning but also incorporates parameter-efficient techniques and optimizations like peft and packing.
Ready to Take Your LLM to the Next Level?
As an expert in fine-tuning Large Language Models, I've helped numerous companies achieve stunning accuracy improvements in their AI applications. If you're looking to customize an LLM for your specific use case or improve its performance on domain-specific tasks, I'd be thrilled to assist you.
With my experience in implementing cutting-edge fine-tuning techniques and optimizing model performance, I can guide you through the process of transforming a general-purpose LLM into a powerful, tailored tool for your organization.
Interested in exploring how we can enhance your AI capabilities? Reach out to me at hello@fotiecodes.com, and let's discuss how we can leverage the power of fine-tuned LLMs to drive innovation and efficiency in your projects.
Post originally published at blog.fotiecodes.com